Spark 从任务提交到内部任务运行和shuffle过程全流程总结
spark提交任务
spark用client模式(为例子)在yarn的调度下提交了任务。 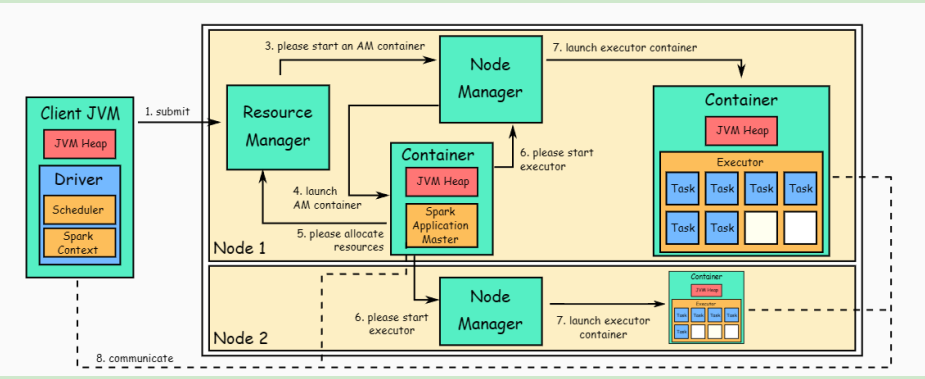
- 客户端提交初始化请求(老大排任务了)
客户端所在的master节点,来提交任务【执行spark-submit】,这个时候Master中就启动了Spark Driver;此时客户端client开始与Yarn的ResourceManager(RM)建立通信,发出启动ApplicationMaster(AM)的请求。(安排一个项目经理)
RM验证后会把相关的信息【application id, HDFS 位置等】返还给client 然后client 会把资源【Jar包、配置文件、第三方依赖等】上传给指定的HDFS位置,并提交作业执行请求
- RM收到client的作业执行请求并开始调度AM了。(资源老大和这个项目经理商量)
现在,RM把这个作业的调度先放在内部调度队列中排队等资源,当集群有资源后,Yarn Scheduler选择一个合适的NodeManager(NM)节点,说现在有个任务你快安排一下(请你给他分配一个Container。 NM分配了一个Container,并在这个容器里启动了AM。【如果是cluster模式那么这个AM就包含了Spark Driver】
- AM 为任务的执行做资源申请(项目经理开始下发任务了)
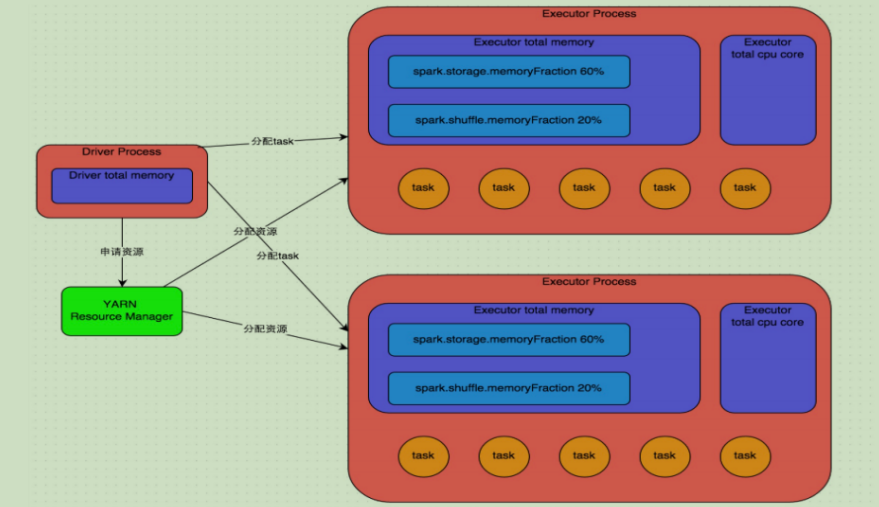
AM启动后,从HDFS上拉去运行任务要的Jar包等,然后 Driver 进程会初始化 代码中的 SparkContext/SparkSession,解析出来DAG图,划分Stage,确定Tasks数量。 接着,AM向RM申请运行executor需要的资源。 RM收到请求,在资源有的情况洗,又叫NM安排Container过去,然后RM会告知AM去找责任人去问。 AM直接与NM通信,然后在分配的container中请求执行executor,NM收到了便启动了container。
当executor启动后会反向注册driver,executor全部启动完后【准备就绪了】,driver便把内部sparkcontext启动的taskscheduler分好的task给executor处理 executor运行Task过程,会给AM随时汇报状态和结果。让AM随时掌握各个任务的情况。
如果task执行失败,driver会有安排重新在executor启动任务; 如果executor失败,AM会检测到然后重新向RM分配资源换一个。
- 回收资源 当spark所有的任务运行完成后,AM向RM申请注销;然后RM会指示NM收回资源,后面Yarn会回收所有的资源(AM、containers..)
Spark任务的执行细节
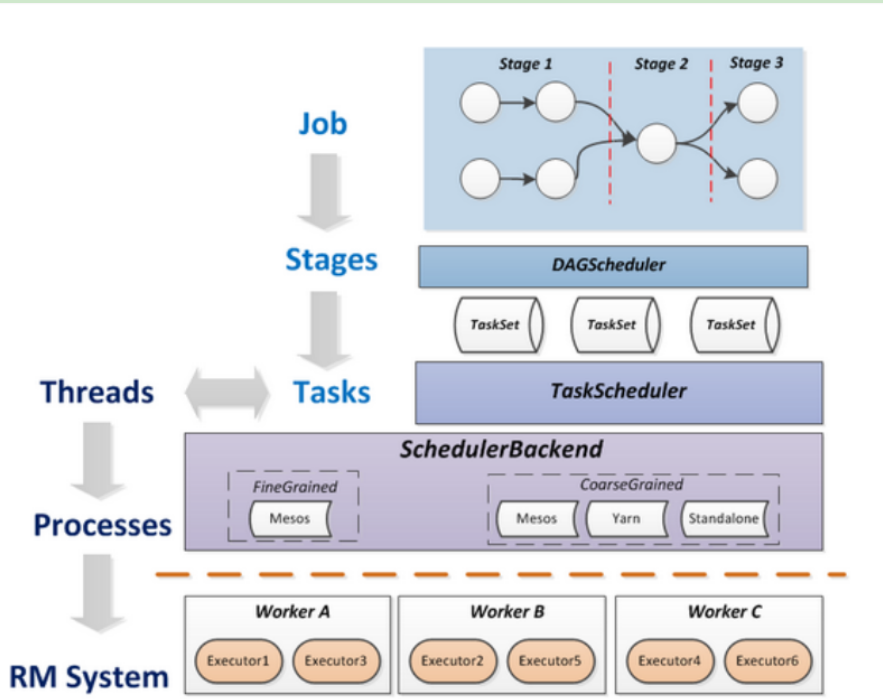
Job=多个stage,Stage=多个不同种task, Task分为ShuffleMapTask和ResultTask等,Dependency分为ShuffleDependency和NarrowDependency task数量由rdd的分区数量决定的。总得来说,一个job task的数量=stage数量*task数量综合
spark去分stage、task的细节:
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。 Driver 进程 会依据 DAG 图我们编写的 Spark 作业代码分拆为多个 stage, 每个 stage 执行一部分代码片段,并为每个 stage 创建一批 task (task 的数量有最后一个操作的rdd的分区数量决定的),然后将这些task分配到各个Executor进程中执行。
task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。task 的执行速度是跟每个 Executor 进程的 CPU 资源情况有关系。
一个 stage 的所有 task 都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果, 然后 Driver 就会调度运行下一个 stage。下一个 stage 的 task 的输入数据就是上一个 stage 输出的中间结果。如此循环往复,直到将我们自己编写的代码 运行完毕。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor。
Stage划分和shuffle的过程
前面提到了,DAG图会分Stage,具体Stage是怎样被分的呢? 当要发生shuffle的操作,那么就会划分stage。在spark中,用了宽窄依赖的概念来解释的。 说白了,shuffle的操作就是数据要进行转换了,数据会更换形态了。在spark中,数据会基于RDD这样的结构来保存数据,使用血缘来记录数据形态的变化。 当发生宽依赖了,也就是数据的分区会发生流转行为,那么就在这里产生shuffle操作,划分stage;对于窄依赖来说,数据的分区并没有流转,那么会归在同一个stage上
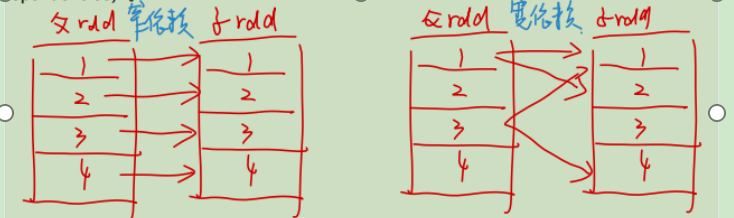
那么哪些spark中的算子会出现宽依赖的情况?
- 重分区: repartition/coalesce… ;上一个stage的数据会打乱,指定给下游新的分区中
- 按键分组:reduceByKey/groupByKey/sortByKey…;按键重写分区了,同分区的要在同一个计算节点上进行处理
- join类型:join/cogroup…;等值join key操作,要把数据都弄到同一个节点上,进行相同key的rdd数据聚合操作
好的,划分好了stage,确定了哪些task会是shufflewrite(对标maptask),哪些是shuffleread(对标reducetask)。
那么对于这二者task具体执行的细节是什么?
Spark shuffle的细节
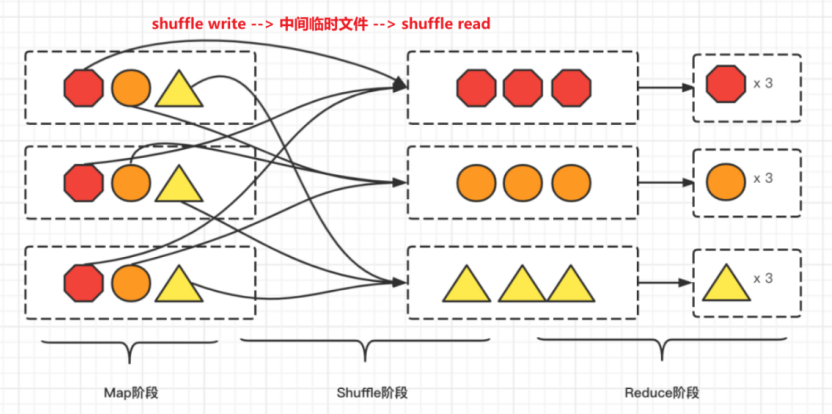
这个过程分两个阶段
1. shuffle write阶段
shuffleMap Tasks中前面的过程都数据都转换完了(窄依赖),进入下一个stage也就是进入shuffle write阶段, 这个时候把数据存在 BlockManager上,并把数据的位置告诉Driver的MapOutTrack组件中,这样下一个stage就能根据这个位置信息找到数据,后面再进行shuffle read阶段。
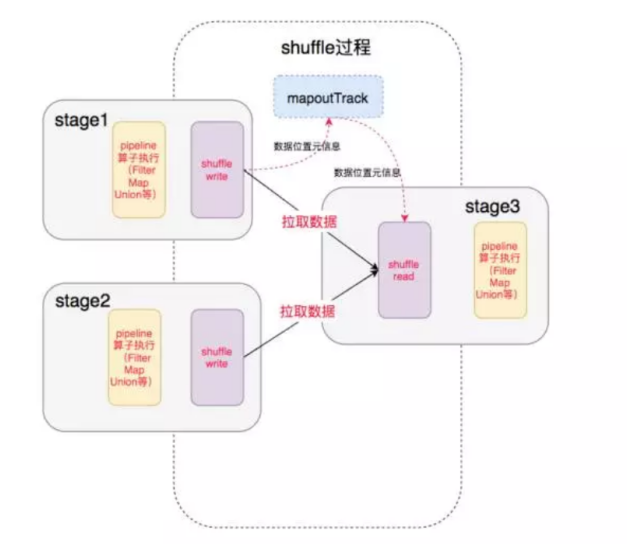
再shuffle write阶段中,就是指写入临时文件的过程。Spark现支持三种writer,分为BypassMergeSortShuffleWriter, SortShuffleWriter 和 UnsafeShuffleWriter。(这一块我们放到后面细讲,不同的Writer再write过程中一些细节不太一样。这也是spark演进的过程)
那么具体是怎么写入临时文件的呢?我们以最开始的 hash shuffle为例子
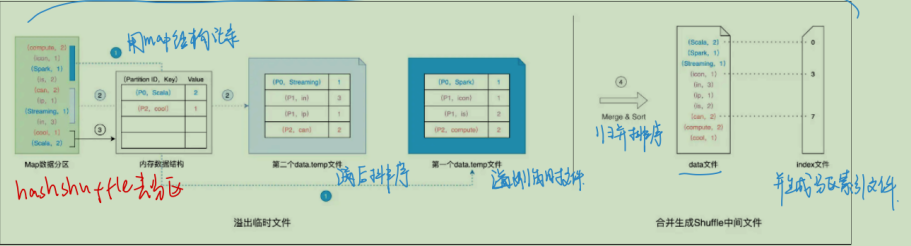
这个过程是这样的,数据再内存中,然后spark会借助类似于map的数据结构来计算和缓存(排序)数据分区中的数据记录。 这种map结构是key是(reduce task partition id, recode key),value是数据值,这样的kv键值对样子。 然后生成中间文件的过程是这样的: 1.计算目标分区,然后填充到内存这个map结构中,一直装一直装装满了后,这个就装完了,如果还有没装进去的数据,按照(目标分区,Key)排序后,对装满的数据和没装进去但排好序的文件溢出为临时文件,溢出后,原先的map结构就空出来了,然后继续这个操作。 2.重复这个操作直到所有的数据都处理完 3.然后把这些一个个的临时文件哈,和有一些尾巴还在map结构中的(因为没装满)都做归并排序,得到总的一个数据文件(中间临时文件),还有一个索引文件 一个 Task 通常只生成一个数据文件和一个索引文件
好了,那么shuffle write 阶段我们喜提 一个中间临时文件和一个索引文件。
2. Shuffel read 阶段
对shuffle map task生成的中间文件,在shuffle reduce task中,会通过网络去拉去数据,不同的reduce task要自己的分区文件,它是怎么找的呢? 用那个index索引文件来确定那个分区是自己的,然后去拉数据,这个过程也就是shuffle read阶段。
整个read阶段流程就不细说了,详见 Spark Shuffle源码分析系列之ShuffleReader
总得一句话,就是把数据拉过来了。然后接着做这个阶段的算子处理
上面这些是大体的shuffle阶段过程,spark在后面的发展过程中,也有很多的改进。
Spark shuffle的演进
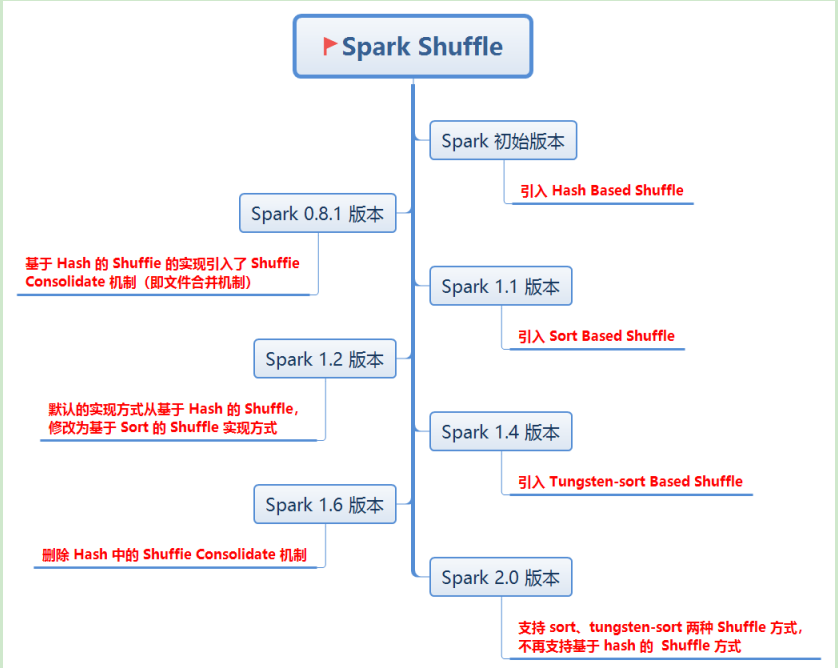
待进一步完善shuffle的细节